
DNNs to Decode Data in DNA
Explaining something that I haven't the slightest idea about

“Mad Hatter: “Why is a raven like a writing-desk?”
“Have you guessed the riddle yet?” the Hatter said, turning to Alice again.
“No, I give it up,” Alice replied: “What’s the answer?”
“I haven’t the slightest idea,” said the Hatter”- Lewis Carroll, Alice in Wonderland
Over the last few weeks, I have been noticing that I pretend a lot. I pretend to know things that I haven’t the slightest idea about - and surprisingly enough, I do this often without noticing it in the moment only to regret it later.
So, I dug into this a little deeper and I figured out that this pretense often shows up with topics that I have heard of and read about at the surface level (and sometimes I want to believe I understand because of how often certain words are thrown around), but don’t fully understand how it works. And now I am on a conscious quest to rework this pattern.
Baby Steps
As the first step, I read my first full paper1 on deep learning (with ample help from Gemini and GPT Deep Research) and how it is being leveraged to store and access data stored in DNA with minimal error rates.
The title of the paper is ‘Scalable and robust DNA based storage via coding theory and deep learning’. Sounds (unnecessarily) complicated. I started by breaking this down.
Scalable and robust DNA based storage is fairly straightforward. It refers to storing binary data in DNA in a manner that enables us to retrieve it without losses or errors (hence robust) and can be leveraged even for larger amounts of data than what has been demonstrated in the paper (hence scalable).
Now what is coding theory? It is a fancy word for a broad set of concepts that enable encoding, decoding and transmission of data in a way that minimizes errors, most often by introducing redundancy. Redundancy refers to adding some extra information to your existing data in order to enable retrieval with minimal errors.
And what is deep learning? This is so much of a buzzword that we all think we know what this means. But I still want to break this down.
Let’s start with what machine learning is. It refers to algorithms that enable computers to identify patterns from pre-existing data that it can now apply to newer data of the same kind. Deep learning is a type of machine learning wherein the process of identifying patterns (i.e. learning) happens across multiple layers of an algorithm, with each subsequent layer becoming more adept at picking out more abstract features than the earlier one. It is because there are several layers that this kind of ML is referred to as deep learning or deep neural networks (DNNs).
The Method in the Madness
The authors of this paper are attempting to retrieve data stored in DNA with reasonable accuracy while minimizing the amount of compute they would need. They call their system ‘DNAformer’. Here is a schematic of how it works.
“Though this be madness, yet there is method in't.”
― William Shakespeare, Hamlet

A few key takeaways:
1. There wasn’t enough data to train a deep neural network on error correction associated with DNA synthesis and sequencing (using Illumina and Oxford Nanopore).
In order to solve this, training data was generated based on a general understanding of synthesis and sequencing errors from a tool called SOLQC which is used for the quality control of synthetic DNA, i.e. it has all the parameters in place for error determination. The important point to note here is that the model isn’t based on identifying specific characteristics such as file structures or semantics of sequences, it is purely trained on filtering out specific kinds of errors that occur frequently, thus enabling the model to be used across structured and unstructured datasets across the board.
This could be a useful approach for generating synthetic data sets for use cases where there isn’t enough data to train models, and it’s too expensive to generate data to train models. However, I am unsure how the reliability of synthetic data sets can be determined, apart from the obvious step of using that to train a model and then testing the efficacy of the model on a known data set. If you have any resources on this, please send them my way.
2. Error correction is not an afterthought (unlike what I assumed)
Indices (or address markers) are added to the sequences to enable them to be sorted into clusters later on. Physical constraints, such as ensuring that the GC content of a DNA sequence is nearly 45-50% to ensure stability of the molecule, are accounted for before the sequence is generated.
3. Speed is prioritized.
Here is what it does as soon as sequencing data is obtained.
a. Clustering
The different DNA sequences are grouped into different clusters based on their indices. This is done fairly quickly based on a sorting algorithm approach, but is likely to be ridden with errors which the subsequent steps (aka the DNAformer) are well poised to correct.
b. Reconstruction
This is where I was stuck at for a really long time as I made my way through the paper. I will try to break it down in as easy a manner as possible.
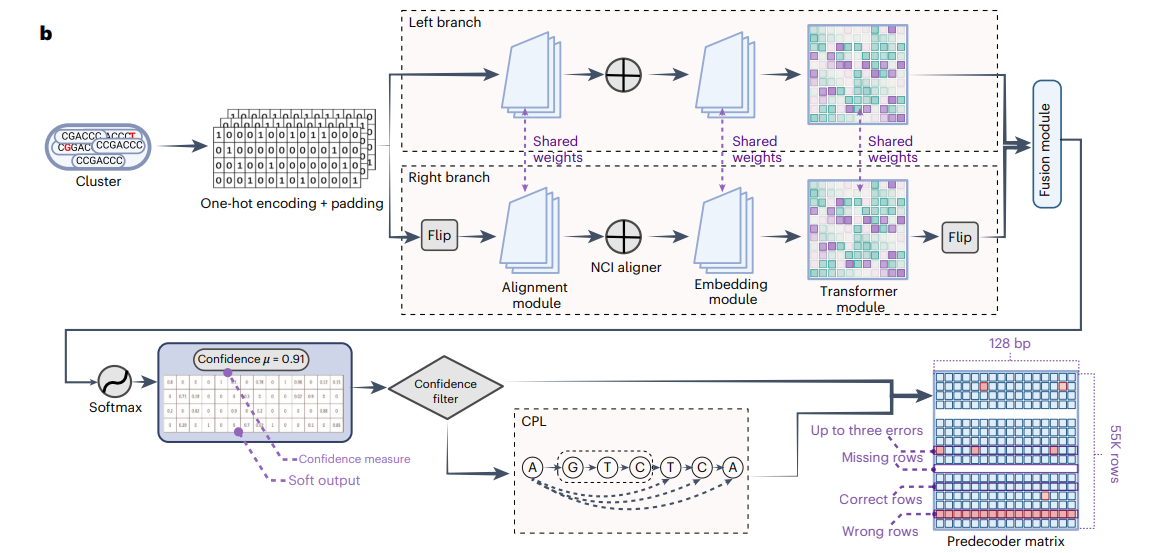
The reconstruction step has three components:
i. Convolutions: These are used to align the sequences and prepare the data for the transformers (that come in the next step). The alignment and embedding modules in the figure above are convolutions.
ii. Transformers: These are used to find long range dependencies in the sequence (eg: how a small part of the sequence at the beginning of a long strand affects a small part in the middle or the end of the sequence)
iii. Confidence filters: Confidence values are assigned to each cluster based on the predictions of convolutions and transformers. This is expressed as a mathematical equation involving the sequence length and expected probability of a nucleotide (A, T, G or C) at a given position.
The confidence filters reject clusters that have a low confidence value and a low cluster size (i.e. number of DNA sequences that got grouped into a given cluster) but wants to get a second opinion on clusters that have a low confidence value but a large cluster size (thresholds for cluster sizes are already set).
The second opinion comes from the CPL algorithm, which is basically a probability based algorithm that compares every sequence to every other sequence and determines where errors could be. Instead of sending every sequence obtained from the sequencer to a sequence alignment algorithm (which does sequential processing as opposed to parallel processing, the latter being faster), this mechanism only sends those clusters that require a second opinion. That improves speed.
c. Decoding
This is straightforward. The sequences that come through the reconstruction step are then converted back to binary based on a converse of the encoding algorithm and error correction codes using a tensor product algorithm. This algorithm has redundancy across two dimensions, and hence enables efficient error correction.
******
That was quite a huge info dump (if you are as new to concepts in deep learning as I am), but attempting to explain concepts to others helps me learn better and I am glad you stuck around. Let me know which parts of these made sense and which ones didn’t, happy to attempt those again.
If you are an expert in the deep learning space and find that I have interpreted concepts incorrectly, do reach out and help me unlearn.
P.S. Shoutout to Ben for helping me access the paper which was originally behind a paywall. If you are curious but don’t have direct access, feel free to reach out I can pass on a copy to you.
Bar-Lev, D., Orr, I., Sabary, O. et al. Scalable and robust DNA-based storage via coding theory and deep learning. Nat Mach Intell (2025). https://doi.org/10.1038/s42256-025-01003-z